I really like the game Fez for so many reasons and I am also the kind of guy that likes to take apart the things I like in order to understand them better.
This morning I decided to poke around at the data for Fez and see what I could discover. As it turns out there are only like 3 files, large ones (~150mb), with the extension ‘.pak’. For games, these large ‘.pak’ files are often used to collect many small game assets into large files, which has many advantages, such as easier distribution, faster loading, file system abstraction and patching.
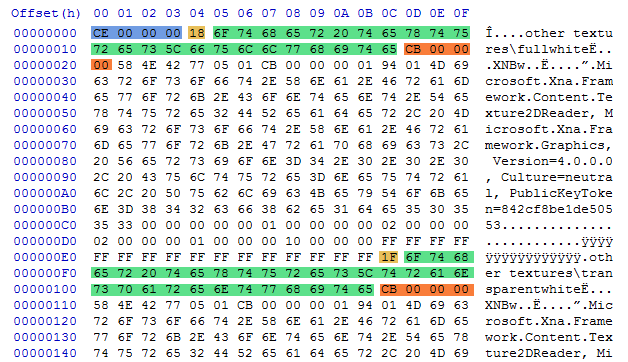
Opening up ‘Essentials.pak’ in HxD hex editor, I saw the following:
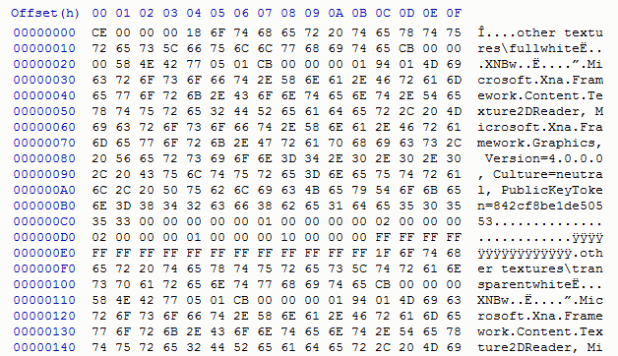
The abundance of strings was a good sign tipping me off that this data is not compressed in any way, making my job of extracting the files vastly easier. The first thing I went after was the path ‘other textures\fullwhite’ since it seems like the name of the first file in the ‘.pak’ file. The string was missing a null terminator, so the size must lurk somewhere else. Preceding the string, was a singe byte 0x18, which sure enough matched the length of the string. I now understood the name of each file in the ‘.pak’, but I still need to know the length of the file itself. Scanning down the file, I can see what looks like the start of another entry, which is good, since it gives me an idea of the length of the first file. The next file starts at 0xE0, so the length of the file must be smaller, and smaller still when we remove the size of the name and ‘.pak’ file header. In total I expect it to be around 0xC0 in size, and sure enough after the string there is 4 bytes with 0xCB.
Its worth noting that any assumptions I make I am sure to verify by looking at other entries in the ‘.pak’ file and seeing if the rules I can see still hold tight. In this case, they do!
I could write a program to start extracting data out of the ‘.pak’ file until it fall off the end of the file, but there will most likely be a way to find the number of files within this ‘.pak’ file. Most likely it is at the start of the file, generally known as a header. The rest of the file has been very simple so I wouldn’t expect this to be any different, the first 4 bytes seem suspiciously close to being a file count.
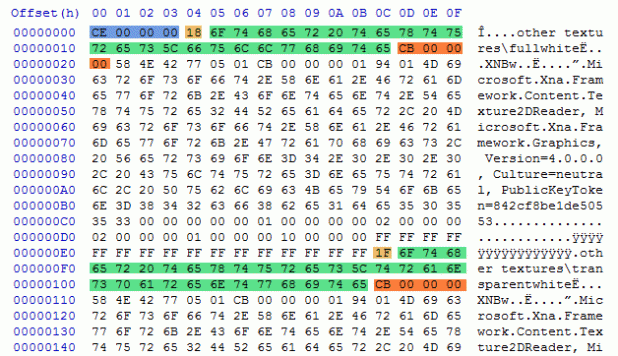
Below I have colored the hex view to highlight the interesting parts. In blue is the file count. Light orange is the string length. Green is the file name and path. Darker orange is the file size in bytes. The data between two entries is the file data itself.
It didn’t take long to code up a simple extractor for these ‘.pak’ files. Some of the goodies inside are all of the stems for the music tracks stored as Vorbis (ogg) streams. These have no file extension, but VLC is able to figure out how to play them just fine. I will in time try to poke around at texture, trixel and the map data.
The source can be found here: FezUnpack.cpp
An executable is here: FezUnpack.exe